小 T 导读:此前,韵达使用 MySQL 分区+索引处理订单数据的方式遭受到了挑战,面对每日亿级的数据量,MySQL 显然已经无法满足当下的数据处理需求。为更好地发展业务,在此基础上韵达新增了 TDengine 的数据源,用专业的数据库来进行时序数据的处理。
作为一家头部物流公司,韵达每日的订单扫描量能达到上亿级,这也是目前公司数据量最大的一块业务。要保证业务的正常运作,系统就需要汇总统计全国网点的扫描数据(韵达的所有订单数据),并实时反馈给用户。此外,这些数据也会给到网点、分拨中心的内部员工使用,用于个人工作量、站点扫描量等统计工作。
在业务尚未扩张之前,我们采用的是 MySQL 分区+索引方式进行此类数据的处理,但随着企业的发展、业务量的增加,面对每日亿级的数据量,MySQL 显然已经无法满足当下的数据处理需求。
在这种背景下,我们决定进行数据库选型。考虑到目前业务主要是统计各个网点设备实时上传的数据,无需再进行修改等操作,是典型的时序数据。经过一番调研,我们发现时序数据库 TDengine 就很符合当下的业务要求,其数据模型与我们的场景十分契合,基于百亿千亿级大数据量的查询性能也很强悍。在对 TDengine Database 进行实际测试与使用后,实际的效果也让我们很满意。
一、落地实践与效果展示
当前我们的架构是 Spring Boot + MyBatis + MySQL + TDengine,TDengine 负责处理时序数据,MySQL 则负责非时序数据的存储及应用,整体架构如下:

由于我们的架构未做迁移,只是新增了 TDengine 的数据源,因此没有增加很多工作量就完成了数据架构的升级。


我们目前使用 TDengine2.2.2.0 版本,在三台 16C 64G 的服务器上部署了集群,数据写入速度大概为每秒 2000 行。根据“一个扫描枪一张表”的模型建表,把设备的地点和站点类型设置为标签。
为了防止设备更换地点导致标签值发生变化,我们选择在建表的时候把地点也放进表名中,这样一来,当地点发生变化后,也能通过新建一张表达到同样的使用效果。比如:scan_6100000000265_790117,代表的就是设备编号为 6100000000265 所在地址为 790117 的扫描枪,当这把扫描枪更换位置的时候,我们可以新建一张 scan_6100000000265_800000 的子表,和旧表区分开,并且同时保留两份数据。
当前,这个超级表下面已经有了近百万子表,经过 1 个多月的正式使用,保存了大约 200 亿行的数据量。

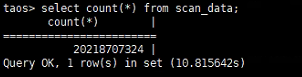
值得一提的是,基于 TDengine 常用的查询基本可以在 1 秒之内完成,一些特定查询甚至可以达到毫秒级:
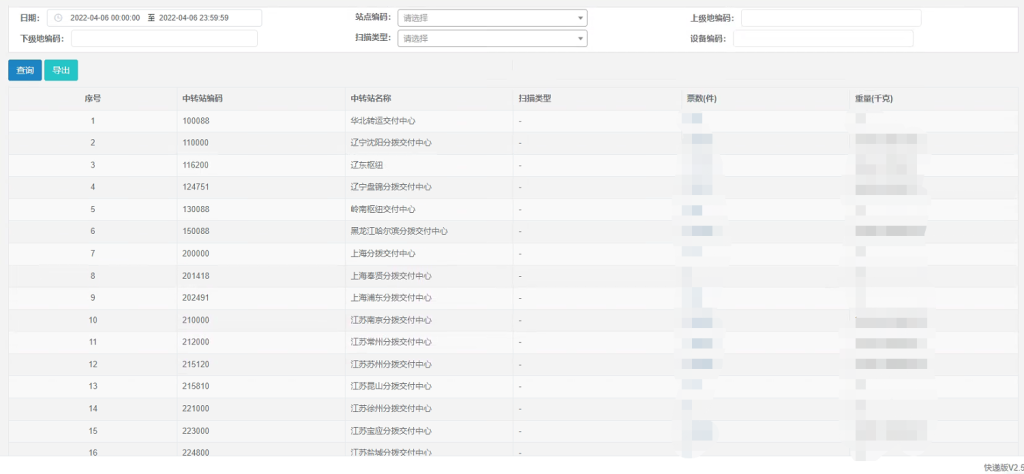
select location,sum(weight_info) as weightSum,count (waybill_barcode) as ticketNum from base.scan_data where ts>='2022-04-07 00:00:00' and ts<='2022-04-07 23:59:59' group by location;

展示效果如下:
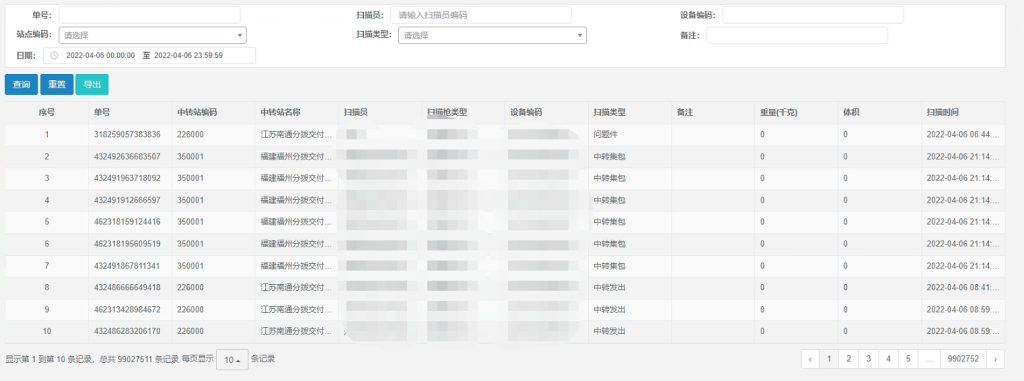
select waybill_barcode,location,scanning_person,scan_category,remark,weight_info weight,scan_time,volume from base.scan_data where ts>='2022-04-07 00:00:00' and ts<='2022-04-07 23:59:59' and site_type=3 limit 0,10;

展示效果如下:
在存储上可以看到,我们的超级表是 20 个字段,大部分是 int 类型,有 5 个左右是 varchar 类型,最大的字段是一个用来存储中文的 500 长度的 nchar ,大约占用300GB 不到的磁盘。而此前使用 MySQL 时,光硬盘使用就需要几个TB,这还没有算上内存和 CPU 等资源,由此可见 TDengine 带来的降本增效是多么显著。
写在最后
当然,TDengine 的测试使用过程中也并非一帆风顺,我们也遇到了一些问题,放在这里供大家参考:
- 由于对数据并发量预估不足,我们使用的默认毫秒时间精度经常会出现时间戳重复的现象,导致数据没能成功入库,后续依靠增加精度解决。
- 超级表如果新增标签,已有数据的标签为 null,需要手动为每个子表更改标签,不够友好。
- 由于 TDengine 建表是单线程所以是有瓶颈的,大概每秒是万张以下,所以在初步搭建环境的时候不建议使用自动建表,如果表数据量不多就无所谓了。
在与 TDengine Database 的社区工作人员反馈之后,以上问题最终都通过参数的配置优化或者合理的使用方式得到了解决,之后我们会考虑把TDengine扩展到更多业务中去。相信随着 3.0 的优化,TDengine 可以更好地融入到韵达的使用场景中,未来我们会有更加紧密的合作。
想了解更多 TDengine 的具体细节,欢迎大家在GitHub上查看相关源代码。





